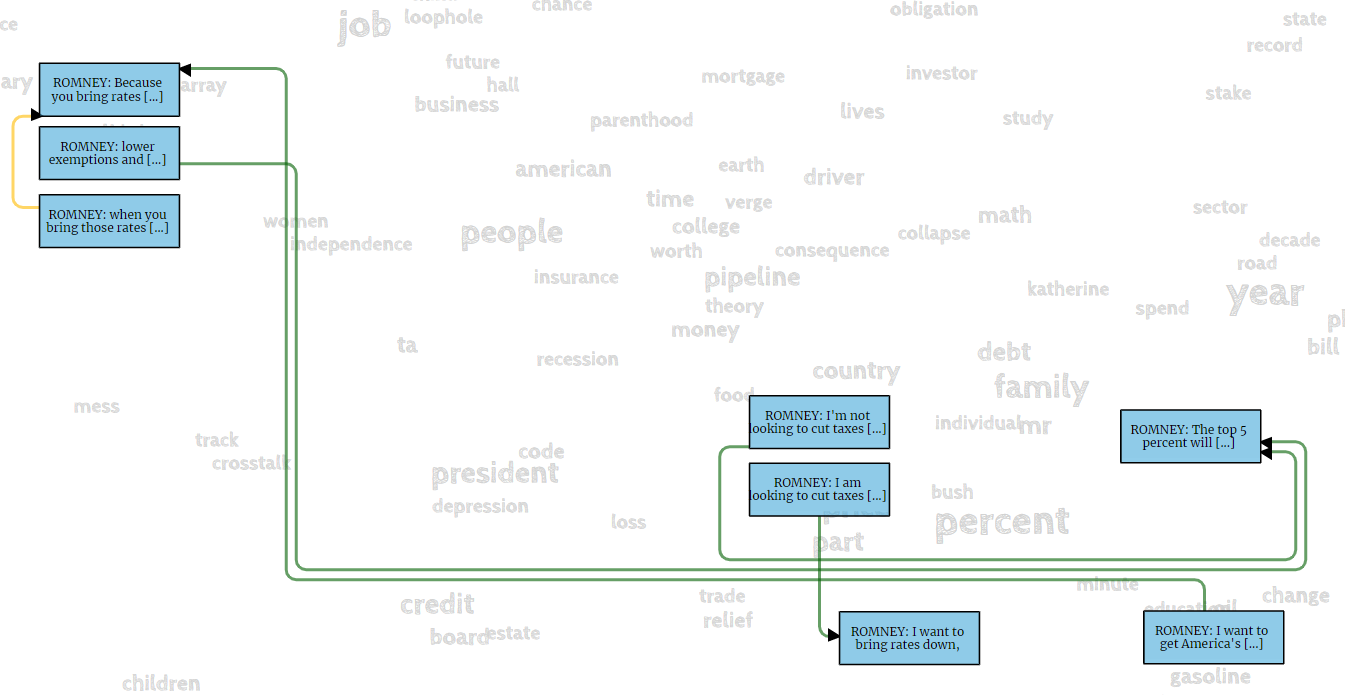
VIANA: Visual Interactive Annotation of Argumentation
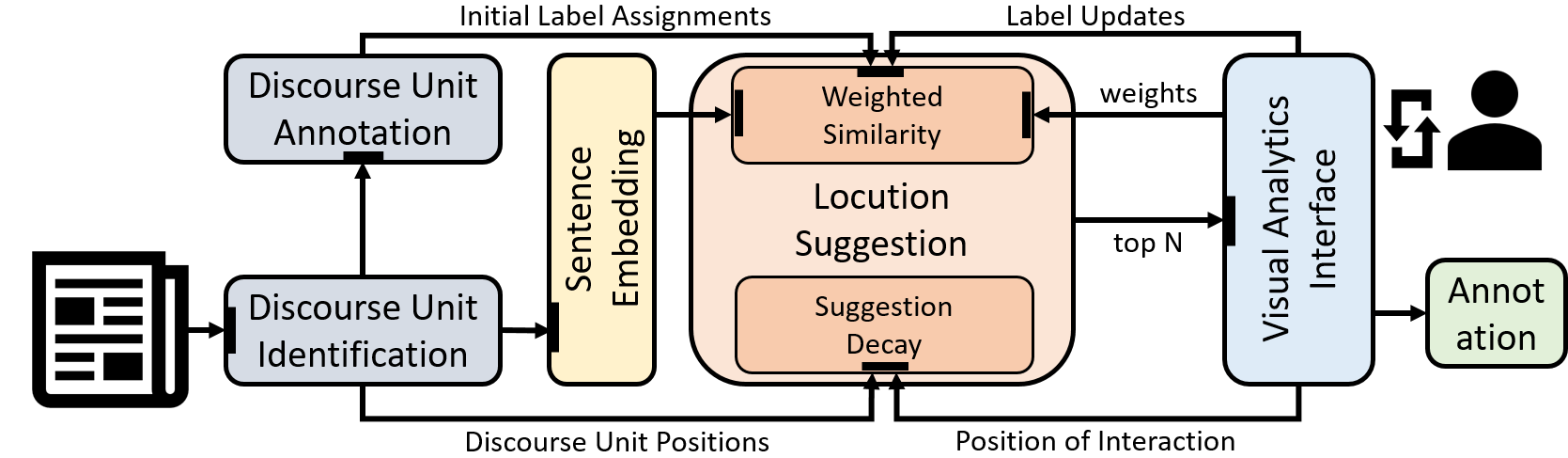
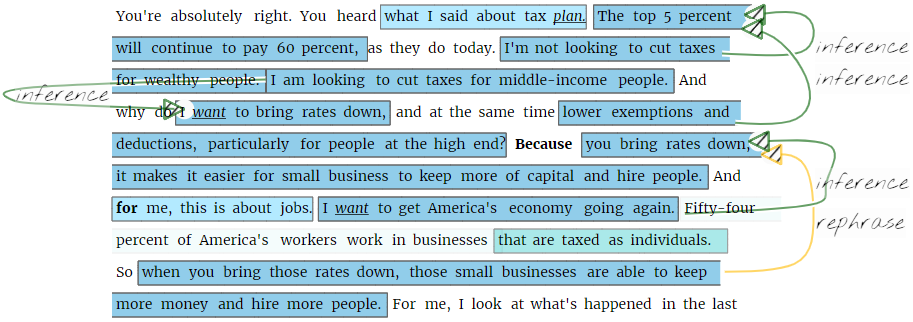
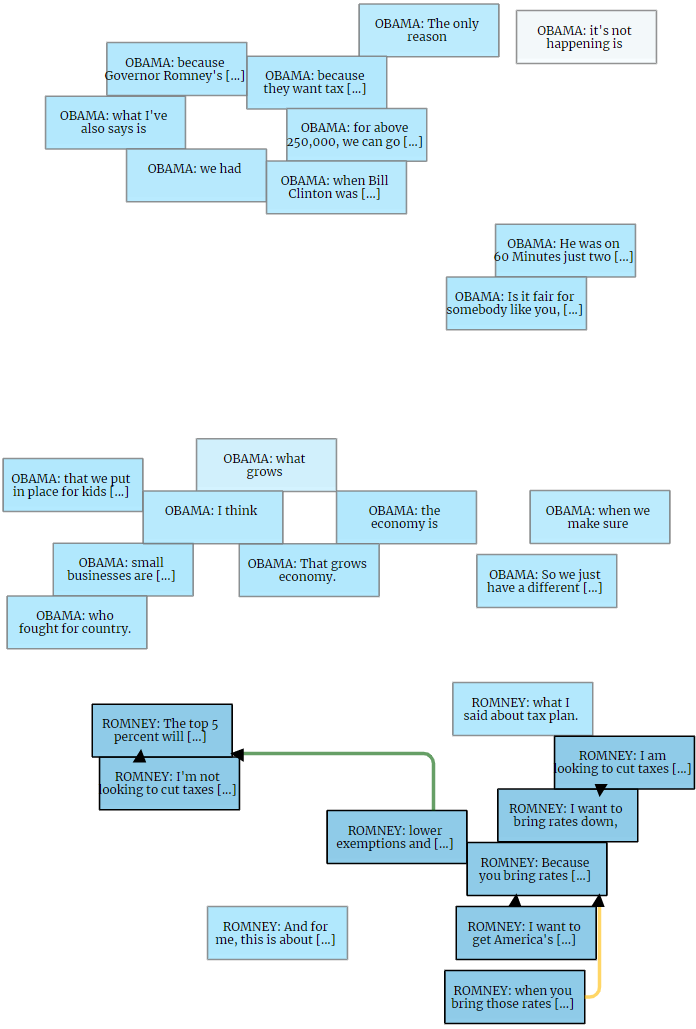
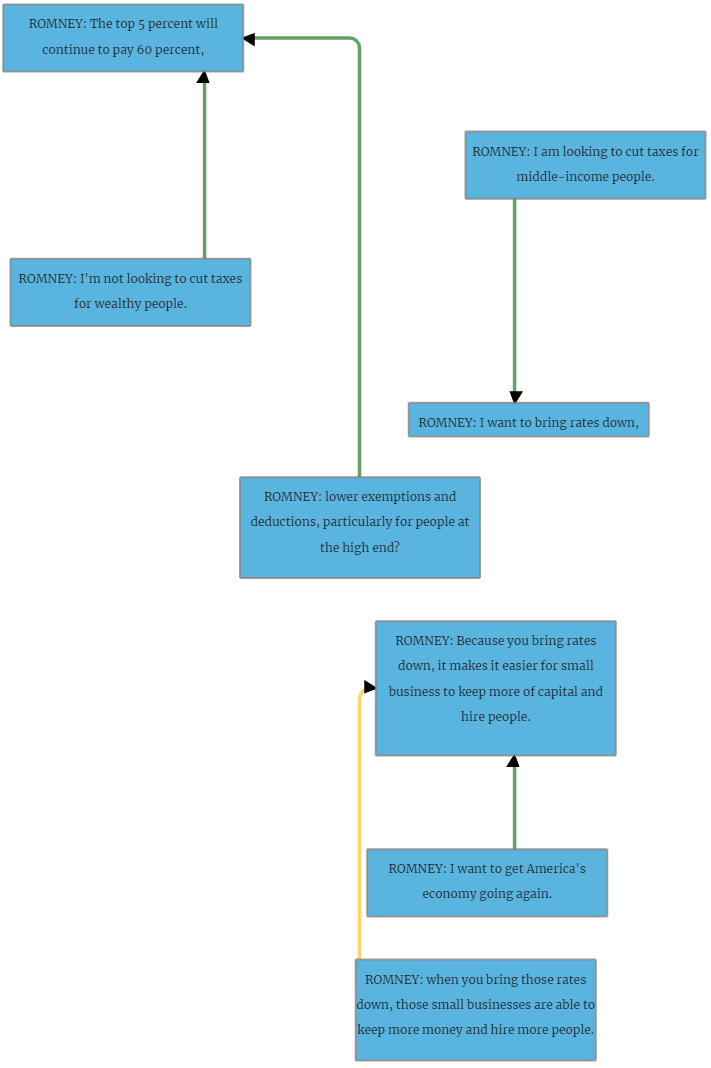
VIANA is an interactive system for the annotation of argumentation according to the Inference Anchoring Theory (IAT). To support users in an efficient annotation, VIANA offers several task-specific interface layers that are connected with semantic transitions. For faster annotation, VIANA analyses user interaction and suggests text fragments for annotation based on linguistic NLP pipelines and previous user interaction.
Check out the Demo